Виды связей в базах данных
MySQL - это реляционная база данных. Это означает, что данные в базе могут быть распределены в нескольких таблицах, и связаны друг с другом с помощью отношений (relation). Отсюда и название - реляционные.
Связи между таблицами происходят с помощью ключей. К примеру, в созданной нами ранее таблице пользователей есть первичный ключ - поле id. Если мы захотим сделать таблицу со статьями и хранить в ней авторов этих статей, то мы можем добавить новый столбец author_id и хранить в нём id пользователей из таблицы users.
Это был лишь один из примеров. Всего же типов подобных связей может быть 3:
- один-к-одному;
- один-ко-многим;
- многие-ко-многим.
Давайте же рассмотрим пример каждой из этих связей.
Один-к-одному
При связи один-к-одному каждой записи таблицы соответствует только одна запись в другой таблице.
Давайте заведем ещё одну таблицу, в которой будет храниться профиль пользователя. В нём можно будет указать информацию о себе и ссылку на профиль в VKontakte.
CREATE TABLE `profiles` (
`id` INT NOT NULL ,
`about` TEXT NULL ,
`vk_link` VARCHAR(255) NULL ,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;Добавим для каждого пользователя профиль:
INSERT INTO profiles (id, about, vk_link)
SELECT id, "Стрессоустойчивость, коммуникабельность", CONCAT("https://vk.com/id", id) FROM users;Посмотрим на получившиеся профили:
SELECT * FROM profiles;
Теперь каждой записи из таблицы users соответствует только одна запись из таблицы users_profiles и наоборот.
INNER JOIN
Прежде чем идти дальше и рассматривать другие типы связей, стоит изучить ещё один оператор SQL - INNER JOIN. Он используется для объединения строк из двух и более таблиц, основываясь на отношениях между ними. Для запроса используется следующий синтаксис:
SELECT столбцы FROM таблица1 INNER JOIN таблица2 ON условие_для_связиЧтобы получить всех пользователей вместе с их профилями нам нужно выполнить следующий запрос:
SELECT * FROM users INNER JOIN profiles ON users.id = profiles.id;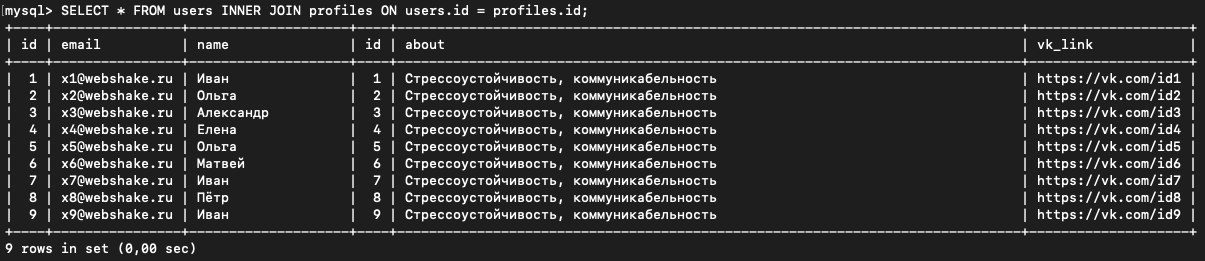
Каждая строка из левой таблицы, сопоставляется с каждой строкой из правой таблицы, после этого проверяется условие.
Если мы хотим выбрать только некоторые столбцы, то после оператора SELECT нужно перед именем поля явно указать название таблицы, из которой оно берется:
SELECT users.id, users.name, profiles.vk_link FROM users INNER JOIN profiles ON users.id = profiles.id;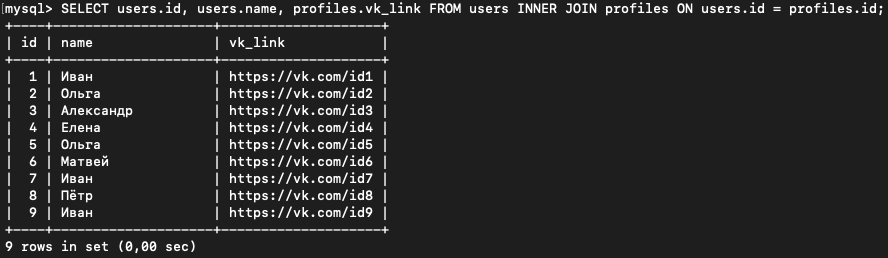
Алиасы
Согласитесь, в прошлом примере пришлось довольно много букв написать. Чтобы этого избежать, в запросах можно использовать алиасы для имён таблиц. Для этого после имени таблицы можно написать AS alias. Давайте для таблицы users зададим алиас - u, а для таблицы profiles - p. Эти алиасы теперь можно использовать в любой части запроса:
SELECT u.id, u.name, p.vk_link FROM users AS u INNER JOIN profiles as p ON u.id = p.id;Заметьте, запрос сократился. Писать запрос с использованием алиаса быстрее.
Как уже говорилось выше, алиас можно использовать в любой части запроса, в том числе и в условии WHERE:
SELECT u.id, u.name, p.vk_link FROM users AS u INNER JOIN profiles as p ON u.id = p.id WHERE u.id=2;
Один-ко-многим
При такой связи одной записи в одной таблице соответствует несколько записей в другой. В начале этого урока мы рассмотрели как раз такой пример, когда говорили о добавлении в таблицу с новостями поля author_id. Таким образом, у каждой статьи есть один автор. В то же время у одного автора может быть несколько статей.
Давайте создадим таблицу для статей. Пусть в ней будет идентификатор статьи, её название, текст, и идентификатор автора.
CREATE TABLE `my_db`.`articles` (
`id` INT NOT NULL AUTO_INCREMENT ,
`author_id` INT NOT NULL ,
`name` TEXT NOT NULL ,
`text` TEXT NOT NULL ,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;Добавим несколько статей:
INSERT INTO `articles`(`author_id`, `name`, `text`) VALUES (1, "Пингвины научились летать", "Шокирующая новость поразила общественность!");
INSERT INTO `articles`(`author_id`, `name`, `text`) VALUES (1, "В городе N обнаружен зомби-вирус", "Шокирующая новость поразила общественность!");
INSERT INTO `articles`(`author_id`, `name`, `text`) VALUES (2, "Котики снижают уровень стресса", "Успокаивающая новость расслабила общественность");Запросим теперь эти записи, чтобы убедиться, что всё ок
SELECT * FROM articles;
Давайте теперь выведем имена статей вместе с авторами. Для этого снова воспользуемся оператором INNER JOIN.
SELECT a.name, u.name FROM articles AS a INNER JOIN users AS u ON a.author_id=u.id;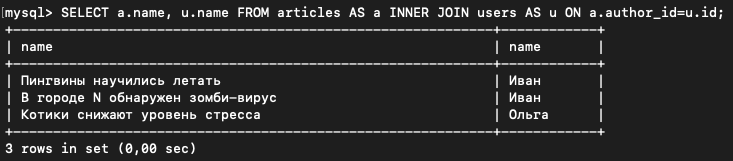
Как видим, у Ивана две статьи, и ещё одна у Ольги.
Если бы мы захотели на странице со статьей выводить рядом с автором краткую информацию о нем, нам нужно было бы сделать ещё один JOIN на табличку profiles.
SELECT a.name, u.name, p.about FROM articles AS a INNER JOIN users AS u ON a.author_id=u.id INNER JOIN profiles AS p ON u.id=p.id;
Изи!
LEFT JOIN
Помимо INNER JOIN, есть ещё несколько операторов класса JOIN. Один из самых частоиспользуемых - LEFT JOIN. Он позволяет сделать запрос к двум таблицам, между которыми есть связь, и при этом для одной из таблиц вернуть записи, даже если они не соответствуют записям в другой таблице.
Как например, если бы мы хотели вывести не только пользователей, у которых есть статьи, но и тех, кто "халтурит" :)
Давайте для начала сделаем запрос с использованием INNER JOIN, который выведет пользователей и написанные ими статьи:
SELECT u.id, u.name, a.name FROM users AS u INNER JOIN articles AS a ON u.id=a.author_id;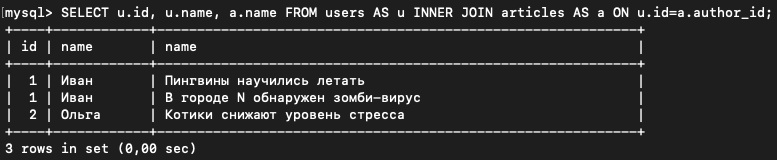
Теперь заменим INNER JOIN на LEFT JOIN:
SELECT u.id, u.name, a.name FROM users AS u LEFT JOIN articles AS a ON u.id=a.author_id;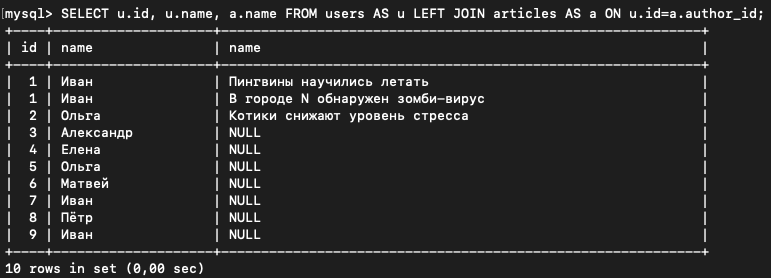
Видите, вывелись записи из левой таблицы (users), которым не соответствует при этом ни одна запись из правой таблицы (articles).
Многие-ко-многим
Такая связь возникает, когда множество строк одной таблицы соответствуют множеству строк другой таблицы. Чтобы связать их между собой, нужно создать третью таблицу, создав с каждой из первых двух связь один-ко-многим.
В качестве примера такой связи можно привести рубрики статей. Каждая статья может иметь несколько рубрик. И одновременно с этим, каждая рубрика может содержать в себе несколько статей. Давайте добавим таблицу для рубрик.
CREATE TABLE `categories` (
`id` INT NOT NULL AUTO_INCREMENT ,
`name` VARCHAR(255) NOT NULL ,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;И сразу добавим в неё несколько рубрик.
INSERT INTO `categories`(`name`) VALUES ("Хорошие новости");
INSERT INTO `categories`(`name`) VALUES ("Плохие новости");
INSERT INTO `categories`(`name`) VALUES ("Новости о животных");Проверим, что они добавились.
SELECT * FROM categories;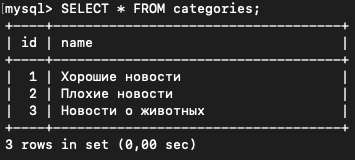
Теперь нам нужно добавить ещё одну таблицу, в которой будут храниться связи между article.id и category.id. Создаём:
CREATE TABLE `articles_categories` (
`article_id` INT NOT NULL ,
`category_id` INT NOT NULL ,
PRIMARY KEY (`article_id`, `category_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;Обратите внимание на составной первичный ключ. Здесь нам требуется, чтобы именно пара (id_статьи - id_рубрики) была уникальной. А сами по себе значения в отдельных колонок могут повторяться.
И давайте добавим нашу новость о котиках в категории:
- Новости о животных
- Хорошие новости
INSERT INTO `articles_categories`(`article_id`, `category_id`) VALUES (3, 1);
INSERT INTO `articles_categories`(`article_id`, `category_id`) VALUES (3, 3);Добавим также новость о вирусе в "Плохие новости".
INSERT INTO `articles_categories`(`article_id`, `category_id`) VALUES (2, 2);а новость про пингвинах в "Новости о животных".
INSERT INTO `articles_categories`(`article_id`, `category_id`) VALUES (1, 3);Посмотрим что у нас получилось:
SELECT * FROM articles_categories;
Теперь давайте выведем рубрики новости о котиках:
SELECT c.name FROM categories AS c
INNER JOIN articles_categories AS ac ON ac.category_id=c.id
INNER JOIN articles AS a ON a.id=ac.article_id
WHERE a.name="Котики снижают уровень стресса";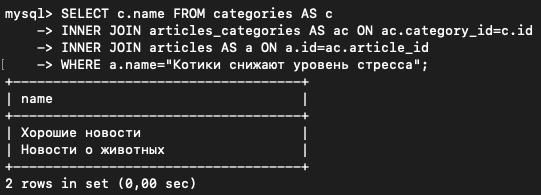
Таким образом реализуется связь многие-ко-многим.

Комментарии